Data Preparation

Executive Summary
Every data science endeavor begins with source data that will hopefully provide insights on a question (business, technical, scientific, etc). Each data set will present with its own characteristic data quality issues that must be identified, characterized, and (if problematic) corrected or mitigated.
The objective of data preparation is to yield a data set that can be effectively analyzed and, if desired, used as a training resource to make predictions with machine learning methods.
The Google slides shown below will step you through the various steps in preparing a challenging dataset for statistical analysis and use in machine learning (shown on a separate page LINK HERE).
Below these slides you will find links to the GitHub repo that holds the python code (in notebook format) used in this project.
Project files include:
This slide presentation will step you through the various steps in preparing a challenging dataset for statistical analysis and use in machine learning (shown in a separate project.
Related jupyter notebook - GitHub repo with the code for this project
Data Preparation Methods:
- Data Quality Assessment
- Create DataFrame from CSV data and navigate through the unprocessed data to begin to identify data issues
- Check for accuracy, completeness, consistency, etc
- Data Pre-Processing
- Cleaning, transforming, and possibly reducing the complexity of data
- Correct spelling and naming format issues
- Drop unnecessary columns
- Check and fix datatypes for correct format
- Clean up monetary data to be integers versus heterogenous string and int
- Check for Missing Data
- Encode categorical variables
- Identify categories by looking for unique values
- Implement a nominal encoding scheme
- Outliers
- Tech Stack shown below
- Create DataFrame from CSV data and navigate through the unprocessed data to begin to identify data issues
- Check for accuracy, completeness, consistency, etc
- Cleaning, transforming, and possibly reducing the complexity of data
- Correct spelling and naming format issues
- Drop unnecessary columns
- Check and fix datatypes for correct format
- Clean up monetary data to be integers versus heterogenous string and int
- Check for Missing Data
- Encode categorical variables
- Identify categories by looking for unique values
- Implement a nominal encoding scheme
- Outliers
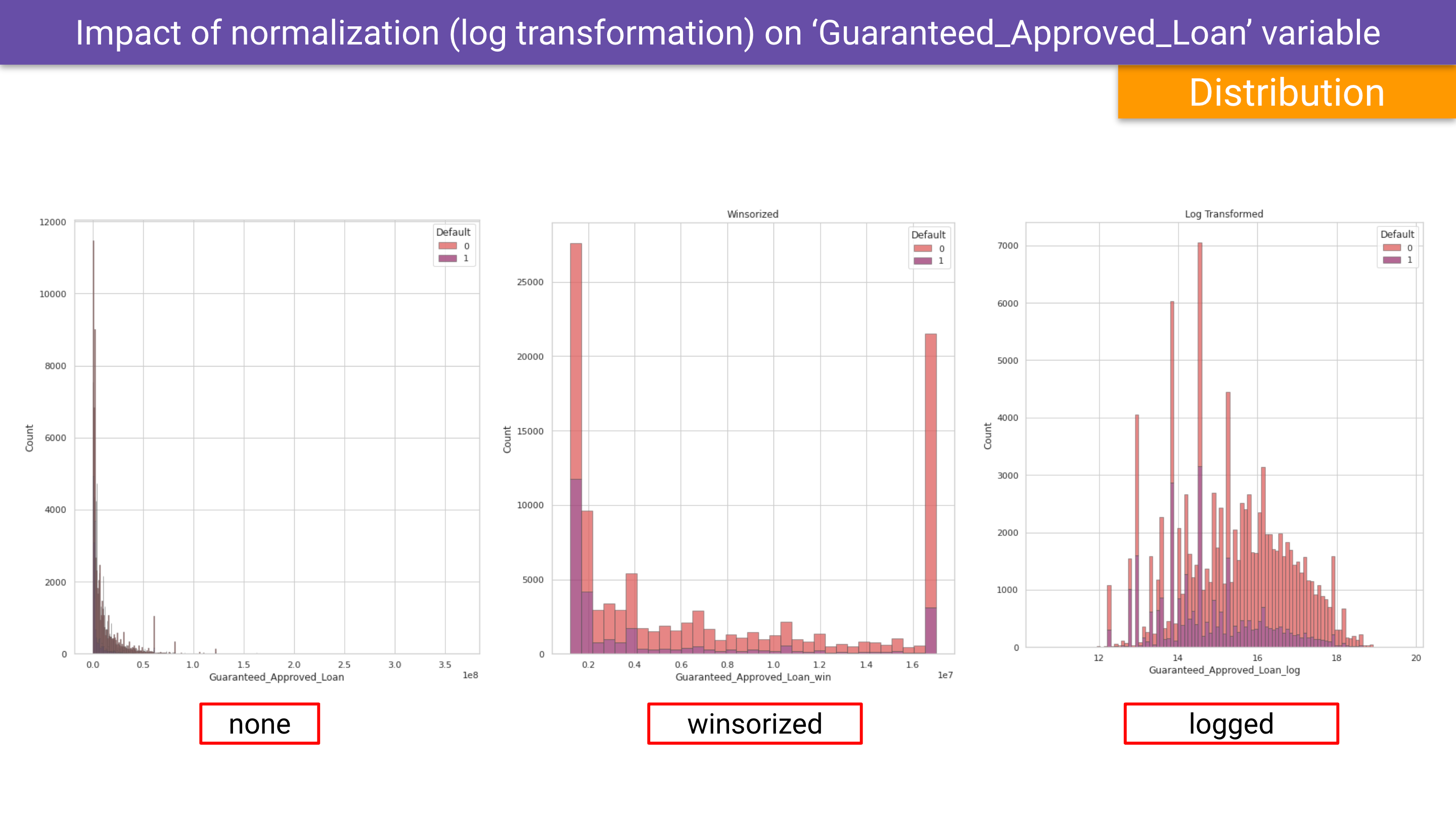
Sample Outcomes
Throughout the notebook and slides shared above you will see a progression from raw data to data that has been cleaned and prepared from statistical analysis and machine learning.
Below are a couple screenshots of data before and after the cleaning methods.